| Luigi Rizzo's home |
| Fabio Checconi's home |
| FreeBSD work |
Geom-based Disk Schedulers
Disk scheduling is a consolidated topic in computer science. Some of the well-known results reached by the research community have been even developed on FreeBSD, but did not made into the main system for a number of reasons.
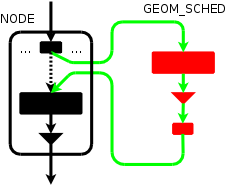 With Fabio Checconi,
we have developed a prototype framework to introduce pluggable disk
schedulers in the Geom layer. It basically consists in a Geom class
that queues up requests going to the provider it is attached to,
and releases them according to the algorithm, which is implemented
in an external module. For a description on what geom_sched
does, please have a look at the
BSDCan 2009 slides
With Fabio Checconi,
we have developed a prototype framework to introduce pluggable disk
schedulers in the Geom layer. It basically consists in a Geom class
that queues up requests going to the provider it is attached to,
and releases them according to the algorithm, which is implemented
in an external module. For a description on what geom_sched
does, please have a look at the
BSDCan 2009 slides
The code is currently (April 2010) available as part of FreeBSD HEAD. A version for FreeBSD 8 and FreeBSD 7 is available as 20100412-geom_sched.tgz
As a quick example of what this code can give you, try to run "dd", "tar", or some other program with highly SEQUENTIAL access patterns, together with "cvs", "cvsup", "svn" or other highly RANDOM access patterns (this is not a made-up example: it is pretty common for developers to have one or more apps doing random accesses, and others that do sequential accesses e.g., loading large binaries from disk, checking the integrity of tarballs, watching media streams and so on).
These are the results we get on a local machine (AMD BE2400 dual core CPU, SATA 250GB disk):
/mnt is a partition mounted on /dev/ad0s1f
cvs: cvs -d /mnt/home/ncvs-local update -Pd /mnt/ports
dd-read: dd bs=128k of=/dev/null if=/dev/ad0 (or ad0-sched-)
dd-writew dd bs=128k if=/dev/zero of=/mnt/largefile
NO SCHEDULER RR SCHEDULER
dd cvs dd cvs
dd-read only 72 MB/s ---- 72 MB/s ---
dd-write only 55 MB/s --- 55 MB/s ---
dd-read+cvs 6 MB/s ok 30 MB/s ok
dd-write+cvs 55 MB/s slooow 14 MB/s ok
As you can see, when a cvs is running concurrently with dd, the performance drops dramatically, and depending on read or write mode, one of the two is severely penalized. The use of the RR scheduler in this example makes the dd-reader go much faster when competing with cvs, and lets cvs progress when competing with a writer.
To try the code
- USERS OF FREEBSD 7, PLEASE READ CAREFULLY THE FOLLOWING:
On loading, this module patches one kernel function (g_io_request()) so that I/O requests ("bio's") carry a classification tag, useful for scheduling purposes.
ON FREEBSD 7, the tag is stored in an existing (though rarely used) field of the "struct bio", a solution which makes this module incompatible with other modules using it, such as ZFS and gjournal. Additionally, g_io_request() is patched in-memory to add a call to the function that initializes this field (i386/amd64 only; for other architectures you need to manually patch sys/geom/geom_io.c). See details in the file g_sched.c.
On FreeBSD 8.0 and above, the above trick is not necessary, as the struct bio contains dedicated fields for the classifier, and hooks for request classifiers.
If you don't like the above, don't run this code.
- PLEASE MAKE SURE THAT THE DISK THAT YOU WILL BE USING FOR TESTS
DOES NOT CONTAIN PRECIOUS DATA.
As usual we make no guarantees on the correctness of the code, though I am routinely using it on my desktop and laptop. - EXTRACT AND BUILD THE PROGRAMS.
On supported systems, the modules (gsched_rr.ko, geom_sched.ko) and libraries (geom_sched.so) are normally built and installed as part of buildkernel/buildworld.
If you are using the archive from this directory, extract the files and do( cd geom_sched && make depend all ) ( cd geom_sched/sys/modules/geom/geom_sched && make $(ENV) depend all ) # this needs root privileges cp -p `find geom_sched -name \*.ko` /boot/modules kldxref /boot/modules cp -p geom_sched/geom_sched.so /lib/geom - LOAD THE MODULE, CREATE A GEOM NODE, RUN TESTS
The scheduler's module must be loaded first:# kldload gsched_rrsubstitute with gsched_as to test AS. Then, supposing that you are using /dev/ad0 for testing, a scheduler can be attached to it with:# geom sched insert ad0The scheduler is inserted transparently in the geom chain, so mounted partitions and filesystems will keep working, but now requests will go through the scheduler. To change scheduler on-the-fly, you can reconfigure the geom:# geom sched configure -a as ad0.sched.assuming that gsched_as was loaded previously. - SCHEDULER REMOVAL
In principle it is possible to remove the scheduler module
even on an active chain by doing
# geom sched destroy ad0.sched.However, there is some race in the geom subsystem which makes the removal unsafe if there are active requests on a chain. So, in order to reduce the risk of data losses, make sure you don't remove a scheduler from a chain with ongoing transactions.
NOTES ON THE SCHEDULERS
The important contribution of this code is the framework to experiment with different scheduling algorithms. 'Anticipatory scheduling' is a very powerful technique based on the following reasoning:The disk throughput is much better if it serves sequential requests. If we have a mix of sequential and random requests, and we see a non-sequential request, do not serve it immediately but instead wait a little bit (2..5ms) to see if there is another one coming that the disk can serve more efficiently.There are many details that should be added to make sure that the mechanism is effective with different workloads and systems, to gain a few extra percent in performance, to improve fairness, insulation among processes etc. A discussion of the vast literature on the subject is beyond the purpose of this short note.
TRANSPARENT INSERT/DELETE
geom_sched is an ordinary geom module, however it is convenient to plug it transparently into the geom graph, so that one can enable or disable scheduling on a mounted filesystem, and the names in /etc/fstab do not depend on the presence of the scheduler.
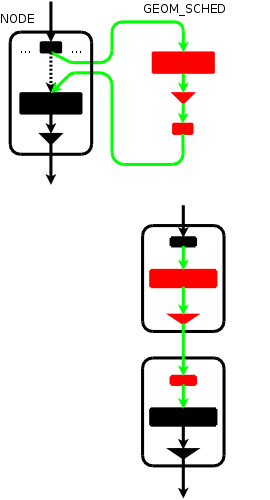 To understand how this works in practice, remember that in GEOM
we have "providers" and "geom" objects.
Say that we want to hook a scheduler on provider "ad0",
accessible through pointer 'pp'. Originally, pp is attached to
geom "ad0" (same name, different object) accessible through pointer old_gp
To understand how this works in practice, remember that in GEOM
we have "providers" and "geom" objects.
Say that we want to hook a scheduler on provider "ad0",
accessible through pointer 'pp'. Originally, pp is attached to
geom "ad0" (same name, different object) accessible through pointer old_gp
BEFORE ---> [ pp --> old_gp ...]
A normal "geom sched create ad0" call would create a new geom node on top of provider ad0/pp, and export a newly created provider ("ad0.sched." accessible through pointer newpp).
AFTER create ---> [ newpp --> gp --> cp ] ---> [ pp --> old_gp ... ]
On top of newpp, a whole tree will be created automatically, and we can e.g. mount partitions on /dev/ad0.sched.s1d, and those requests will go through the scheduler, whereas any partition mounted on the pre-existing device entries will not go through the scheduler.
With the transparent insert mechanism, the original provider "ad0" is hooked to the newly created geom, as follows:
AFTER insert ---> [ pp --> gp --> cp ] ---> [ newpp --> old_gp ... ]
so anything that was previously using provider pp will now have the requests routed through the scheduler node.
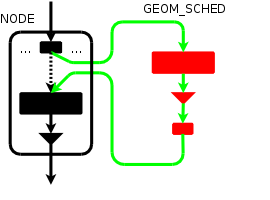 A removal ("geom sched destroy ad0.sched.") will restore the original
configuration.
A removal ("geom sched destroy ad0.sched.") will restore the original
configuration.